
【论文阅读·推荐系统】Matching User with Item Set:Collaborative Bundle Recommendation with Deep Attention Work
以下解读均为本人个人见解,如有曲解或造成不必要的麻烦,欢迎联系我 nexisato0810@gmail.com 进行修改。正文内容中的“作者”均为paper作者本人,我的观点会由“我”或在括号“()”内显式注明。
【Paper作者】:Liang Chen, Yang Liu, Xiangnan He, Lianli Gao, and Zibin Zheng.
【一句话总结】:利用注意力机制和多任务学习的思想,提出了一种新的捆绑推荐模型.
【Introduction】
推荐系统的发展对于减轻信息过载、提升用户体验、增加服务商流量而言,已被证明为一种非常有效的方法. 类似于信息检索,推荐本质上就是估计用户和商品之间的匹配分数. 在现实世界中,应用提供商需要向用户推荐一组而非单个物品,比如网易云音乐的每日推荐、家具的套装等等,这种推荐任务我们称之为 “捆绑推荐”.

在电商平台,捆绑推荐常用于促销活动中,比如可以以一定折扣购买一组商品,从而提高那些很少被单独购买的商品的曝光量. 常用的捆绑推荐策略是按照某种准则将不同商品合为一组(如上图的电子产品按照功能互补关系进行捆绑销售),再建模分析用户对于这些捆绑组的喜好. 在捆绑推荐系统上线之后,我们可以根据用户的行为日志,改进推荐策略.
我们假设在用户和捆绑组之间,存在着一定数量的交互行为,这个数量可以反应用户对于这个捆绑组的偏好. 如果利用协同过滤,将一个“捆绑组”视为单个商品,会有如下难题:
- 非原子性: 一个捆绑组里的商品可能并不是同一类的,不同商品具有不同特征.
- 交互稀疏: 只有当用户对于这个捆绑组里大部分商品都满意时,才会选择购买. 况且只要替换掉其中一个物体,就形成了一个新的捆绑组,因此用户和单个“捆绑组”的交互可能会更加稀疏.
基于此,这篇paper提出的DAM(Deep Attentive Multi-Task)捆绑推荐策略解决方案如下:
- 聚合物体的嵌入信息,用来表示捆绑组的特征,并引入了分解的注意力机制网络,捕获不同用户偏好同一个捆绑组的原因;
- 集成了用户—物品嵌入信息,共享用户嵌入和物品嵌入信息进行对用户—捆绑组、用户—物品喜好进行预测. 模型训练采用 多任务耦合 方式,用户—物品 喜好预测视为一个任务,用户—捆绑组 喜好预测视为另一个任务,从而模型在任务之间进行转移.
【模型构建】
-
输入: 用户集合 , 物品集合 ,捆绑包集合 , 捆绑包中的组成物品 ,用户—物品交互矩阵 , 用户—捆绑包交互矩阵 .
-
输出: 对于每个用户 ,对捆绑包 的喜好函数 .
不过事实上,有一些新的捆绑组并没有出现在集合 中,比如有些电商平台向用户推荐一些新一组的促销商品,这要求模型还要对未出现在集合 中的捆绑组进行评分.
捆绑组特征学习
一个捆绑组包含ID+组成物品两部分,此处将物品 物品对应到嵌入向量 ,然后聚合一个捆绑组中所有的物品嵌入信息,得到这个捆绑组的嵌入信息. 但是如何聚合是个很大的问题,需要针对一个组中不同物品的重要性进行加权、针对不同用户对加权方案调整,因此,作者利用注意力机制,设计了一种自适应加权、求和、运算的捆绑组嵌入信息计算方案,公式如下:
其中 代表第 $s $ 个捆绑组的嵌入信息; 表示用户 和 这个捆绑组进行交互时,物品 所占的权重,为了减少捆绑组大小的影响,引入了L1正则化进行调整.
根据注意力机制,需要在用户嵌入和物品嵌入层上面加上一层 多层感知机 ,用来估计这个权重大小. 由于大多数情况下,观测到的用户和物品之间的交互关系是稀疏的,因此使用下面的低阶模型估计权重(称为分解注意力机制网络)
其中, 是物品 的物品注意力向量, 表示用户嵌入向量,这是为了涵盖到用户可能单喜欢物品 ,但不喜欢捆绑销售的情况.
用户—捆绑组交互 和 用户—物品交互 的联合建模
得到用户嵌入和捆绑组嵌入之后,可以构建用户—捆绑组预测映射模型:
关键还是得到映射函数 ,作者选择了 NCF (Neural Collaborative Filtering)框架,它具有神经网络结构,适用于对嵌入信息进行集成;且可以添加多个非线性层进行学习,得到复杂的映射函数.
用户—物品交互的预测映射模型定义为:
现在要考虑如何将两个任务进行关联,直观的解决方案是分别使用多层感知机作为映射模型:
对于这两个预测任务而言这还不够,还需要从对方的预测模型中提取出信息,而现在这两个MLP的参数却是相互独立的,对此,作者提出了如下的共享MLP层架构
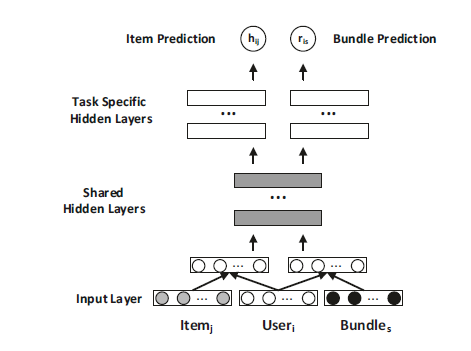
得到新的预测模型如下:
这种利用隐层将两个相关的预测任务进行联合. 架构在推荐系统领域还没有被提出过,从计算机视觉领域的低层卷积得到的启示思路.
现在考虑用户 和捆绑组 ,如果它们之间没有交互行为的话,是不能说明 对于捆绑组 没有兴趣的,因为用户可能并没有了解到这个捆绑组的渠道. 由此,作者采用 BPR(Bayesian Personalized Ranking) loss 进行捆绑组loss设计
其中, 表示与用户 交互过的所有捆绑组,将 视为正例,将 视为负例, 是一个 sigmoid 型函数, 表示捆绑组喜好预测任务中的模型参数,并且引入了 正则化.
类似地,用户—物品喜好预测任务的损失函数设计采用同一组思路
其中, 表示与用户 交互过的所有物品,将 视为正例,将 视为负例, 是一个 sigmoid 型函数, 表示物品喜好预测任务中的模型参数,并且引入了 正则化.
【实验方法】
-
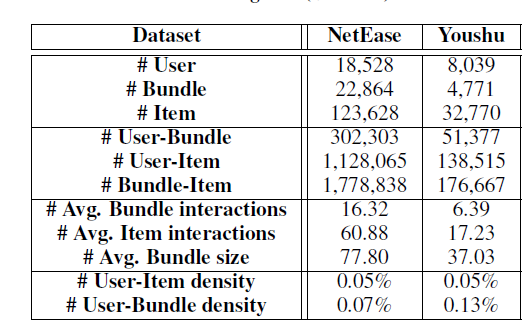
数据集: Netease数据集,爬取自网易云音乐的用户歌单;Youshu数据集,爬取自优书的书单. 统计信息如下
-
-
**性能指标:**采用了留一法. 对于每个用户而言,其中的一次交互被随机除去用来测试. 采用top-K评价策略,关注如下两个指标
- Recall@K:前K个推荐组中,正例物品的数量
- MAP@K:前K个推荐组中,正例物品的排名位置
为了节省时间,作者对每个用户各随机选了99个未交互的捆绑组(歌单、书单),用作负例.
-
对比模型: BPR、NCF、BR、EFM
性能对比
评价指标基于Top-K策略,在设置不同嵌入向量维度的情况下,性能对比如下:
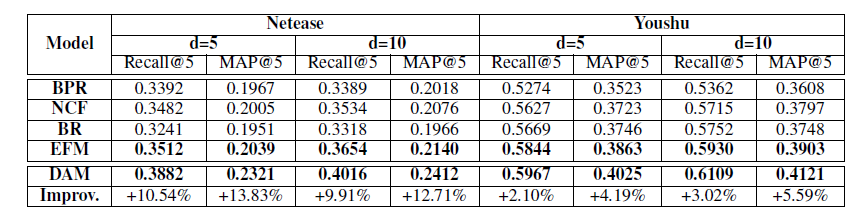
BPR表现不佳,因为用户和捆绑组之间的稀疏交互限制了这种直接用内积进行建模的方法;除此之外的模型都采用了神经网络架构,证明了深度神经网络用来学习用户—捆绑组交互的非线性特征的有效性. DAM联合考虑了用户与捆绑组、用户和物品之间的交互关系,利用注意力机制动态调整各物品的推荐权重,采用了多任务学习框架,因此表现出了最佳的性能.
分解注意力机制的作用
作者将分解注意力机制和其他嵌入结合策略如平均池化、神经注意力机制进行了对比,结果如下
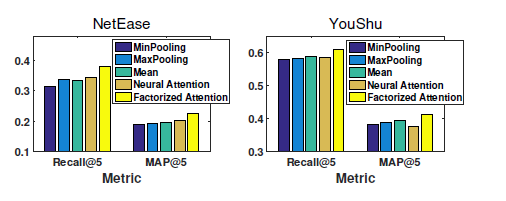
由于分解注意力具有动态调整各物品推荐权重的功能,因此可以捕获到不同物品之间的复杂关系,表现出了最佳的性能. 尽管神经注意力机制也能起到动态调整的作用,但是作者的方法具有更好的泛化性能.
共享层的作用
此前实验的共享层设为2层,为了研究它的作用,作者分别设置了不同的层数进行实验,表现出的性能如下:
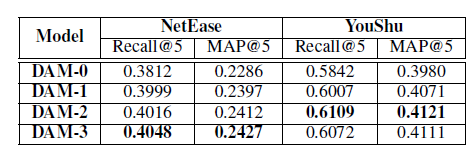
比较来看,多任务学习模型的效果要优于单任务学习模型. 适当增加共享层的数量可以使得推荐系统模型性能更好,但过多的共享层会引入无关噪声数据,对模型性能造成影响.
【总结】
本文提出了一个新的深度注意力多任务模型,用于捆绑推荐任务. 先是采用分解注意力网络,将每个捆绑组中的物品信息进行聚合,再提出一个多任务神经网络模型,共享用户—物品和用户—捆绑组的信息,并通过进一步实验验证了两种方法的有效性.
【后记】
如何将具有相关性的信息结合并利用起来,作者从CV中得到了启示. 对于难以进行同步的信息,就加入一个中间层进行整合,这与目前CV从NLP领域采用Transformer等结构的思想是类似的. 而且可以看到,作者并没有使用特别复杂的模型架构,结构简单清晰,更值得被应用. 关于本文的改进方法可以从以下几点考虑:
- 未能考虑到物品和物品之间的互补性,比如买一套电脑时的键—鼠,应当成对互补,这在本文的模型中并没有很好的利用起来;
- 用户的兴趣会随着时间的推移而改变,如网易云音乐的每日推荐也会随着用户喜欢风格的改变而改变,因此在捆绑推荐任务中还需要考虑到时间的影响.