
【论文阅读·AIOps】Seer:Leveraging Big Data to Navigate the Complexity of Performance Debugging in Cloud Microservices
以下解读均为本人个人见解,如有曲解或造成不必要的麻烦,欢迎联系我 nexisato0810@gmail.com 进行修改。正文内容中的“作者”均为paper作者本人,我的观点会由“我”或在括号“()”内显式注明。
【Paper作者】:Yu Gan,Yanqi Zhang, Kelvin Hu, Dailun Cheng, Yuan He, Meghan Pancholi, Christina Delimitrou, 来自Cornell University团队
【一句话总结】:利用AI模型预测并防止微服务集群的QoS异常.
【Introduction】
服务质量(Quality of Service, QoS),严格限制了云计算服务的吞吐量. 要在性能限制下进行应用的敏捷开发迭代,微服务概念近年来越来越火热. 与其将所有功能包含在一个庞大的二进制文件中作为单体服务(Monolith),耦合数百个关注单一功能的微服务自然是一个更好的选择,既可以加速应用的开发部署,又可以隔离环境进行调试.
由于微服务之间的依赖关系,每个单独的微服务要求的尾部延迟要比传统云服务的单体应用高很多,单个行为不当的微服务会造成整个系统的级联QoS违规. 我们期望对系统服务性能可以预测,基于这样的需求,促进了许多对性能追踪、监管和调试系统的研究,可以帮助云服务提供商检测QoS异常,并帮助纠错,恢复系统性能. 但是这样的后验QoS异常检测对于微服务而言,异常热点早就已经在整个系统中广泛传播.

上图显示了社交网络应用在发生QoS异常后做出的反应,可以看到,后验QoS异常检测是在违规行为发生后,再进行处理的,在处理过程中服务长期处于低性能状态,从50s发生异常,到225s恢复,耗时非常长.

左图为后端到前端订阅了所有微服务的情况下,CPU随时间推移的利用率;右图为尾部延迟随着时间推移的变化. 可以看到,在右图中,由于前端依赖于后端服务,在后端出现QoS异常后,前端会随着时间推移也会发生尾部延迟的现象. 而在左图中,资源利用率并不会出现类似的,从后端到前端随时间增大的现象,这是因为部分前端服务会保持着高资源利用率的状态,因此,使用资源利用率这一指标指导QoS异常检测,说服力并不足.
对此,paper提出了Seer模型,利用轻量级的分布式RPC级追踪系统的日志记录信息,跟踪记录未完成的requests,并利用这些信息训练神经网络,提前识别QoS异常;在硬件级别,Seer使用每个硬件节点进行详细监控,并向这些节点提供相关操作建议,以避免QoS异常的发生.

作者团队经过在大规模社交网络应用中的实际部署,验证了Seer的先验QoS异常检测准确率非常高,并成功避免了其中的绝大部分异常.
【端到端的微服务应用】
截止到论文发表时间(before2019.4)前,还没有公开可用的、架构相对复杂完整的端到端微服务应用程序,因此作者团队设计了四个端到端微服务应用:社交网络、媒体服务、电商网站、银行系统. 此外还基于Go的微服务架构开发了一个酒店预订系统,所有微服务全部部署在Docker容器中.

上表是这几个服务的通信协议、微服务数量、语言技术栈. 以社交网络的微服务架构图为例

用户在Client端通过http发送请求,经过负载均衡器,到达指定的webserver,通过post请求向其他用户发送多种格式的消息,并广播给关注者,且可以与其他用用户post的信息进行交互,其中广告、推荐系统等引擎等利用了机器学习插件,后端米用memcached缓存用户交互信息,mongoDB永久保存用户状态.
社交网络应用部署在了Cornell等地,将与其他几个端到端微服务应用一起用于测试Seer模型的有效性和可扩展性.
【Seer如何设计】
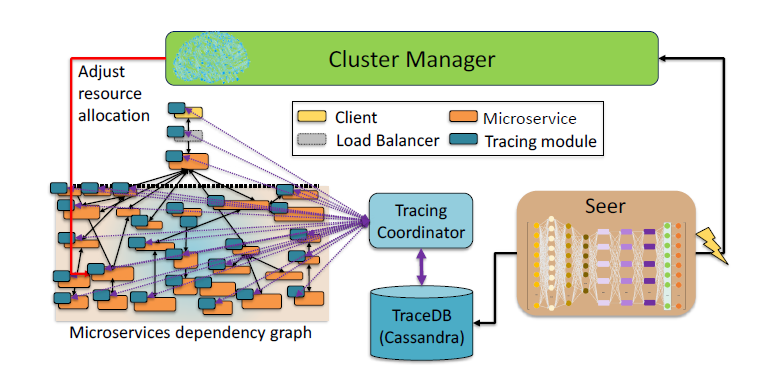
总体概述
Seer的整体架构如上图所示,由于每个微服务应用都部署在了Docker容器中,因此高层的RPC追踪系统可以在每个容器中的Tracing module,收集这些用户请求信息,并将它们收集在Cassandra数据库中,作为Seer的训练数据来检测QoS异常. 在运行时阶段将会通过预训练模型检测潜在的QoS异常. 低层的硬件节点用于发掘QoS异常来源,并向 Cluster Manager提供如何避免性能下降的建议并对微服务节点调整分配资源.
分布式追踪系统

如上图,分布式追踪系统记录了每个容器的微服务尾部延迟,并且根据任务队列的长度记录未完成请求的任务数量,这些追踪信息全部保存在TraceDB中心化数据库中.
深度学习模型用于性能调试
出发点在于,我们并不总能事先得知造成QoS异常的模式;其次,DNN假设在这些微服务之间不存在依赖关系的先验知识,这个对于那些更新频繁的服务来说更适用;且深度学习技术在这些模式识别检测问题中已被证明十分有效,因此这个模型使得Seer以高精度检测QoS异常.

Seer中使用的深度神经网络架构如图所示,由CNN和LSTM层组成。输入输出神经元对应微服务,按照后端->前端的拓扑顺序从上到下排序.
输入值:每个微服务请求队列的深度(能够较为精准地反应性能瓶颈),
输出值:每个微服务发生QoS异常的概率.
作者团队提出,为了提高Seer对于系统性能的可预测性,需要有一定的松弛时间用于模型推理,这样才能使得集群管理器的操作生效. 在这样的大规模微服务集群中,既需要识别空间模式,如识别造成QoS异常的微服务集群并丢弃噪声模式;又需要识别时间模式,如用过去的QoS异常模式去预测未来可能发生的. 对此,需要利用CNN的空间模式敏感性,对海量数据降维,过滤掉不影响端到端性能的微服务异常模式;又需要LSTM的时间模式敏感性,结合SoftMax分类层,推断出对应微服务造成QoS异常的概率.

如上图所示,采用CNN+LSTM结构,成功预测了超过90%的QoS异常模式,解决了单CNN架构无法及时预测、LSTM架构在过量请求的情况下误报的问题.
要训练这样一个模型,要记录一周的跟踪日志,并且训练耗时长达几个小时甚至一天. 对于更新频繁的微服务而言,从零开始学习的时间成本太高. 有一种方式是迁移学习,将预训练权重模型先存储在磁盘,作为检查点,当微服务更新时,允许它从上次训练停止的地方继续训练,但这并不是一个长期的方案. 训练得到的权重受到了旧数据的污染,在微服务有关键重大更新时,还是需要重新训练. 采用的方案为:当新网络进行训练时,增量模型用于QoS异常检测.
硬件检测
Seer通过访问性能计数器进行底层监控,确定QoS异常源.
- 当Seer对性能计数器具有访问权限时,可以依靠它们检查不同的资源利用率,如CPU、内存占用等,一旦识别到饱和资源,便会通知集群管理器采取措施;
- 当没有权限访问性能计数器时,Seer会依靠多组“微基准”,对相关的资源进行调整测试,再观测系统性能是否会发生实质性的变化,若有则通知集群管理器采取措施.
集群管理器可以调整Docker容器大小、CAT、LLC等技术进行资源重新分配.
Seer已经部署在了多个社交网络服务中,对于QoS异常预防检测有了极大的帮助,并为微服务应用的构建提供了很多新的设计思路. 然而,Seer的数据安全性并没有得到很好的保证,用户敏感信息未经加密存储在中心化数据库Cassandra中,仍有受到恶意攻击的隐患.
【Seer的性能分析和验证】
作者团队除了用20台服务器搭建了一个专用的本地集群,还将之前5个端到端的微服务应用部署在Google Compute Engine和Windows Azure集群中,包含数百个服务器,用于验证Seer的可扩展性. 评估了以下三个指标:
- 训练数据敏感性:
-

- 如图显示了Seer的QoS异常检测精度和训练时间随数据集大小的变化,可以看到在100~200GB大小的数据集会使得Seer的检测精度趋于稳定,超过此大小对于Seer的性能提升不会有明显的帮助.
-
- 追踪频率的敏感性:
-
- 如图显示了Seer的QoS异常检测精度随着任务队列采样时间间隔(或频率)变化的曲线,作者团队据此在剩下的工作中选择100ms的采样间隔(文中也用 预测窗口 表示这个含义).
-
- 误判:
-
- 如图显示了Seer的误判率(FP、FN)随着采用时间间隔变化的统计,由于Seer应用了深度学习模型,推理需要一定的时间,采取相应的纠正措施也需要一定的时间,因此需要10~100ms的预测窗口,此处作者选择100ms.
-
- debug系统对比
-
- 如图,对比了采用资源利用率Utillization为指标、只适用应用层日志信息的App Only、只适用NIC队列信息的Net Only、采用双层信息的Seer模型 用于预测异常的结果和真实结果的标签,结果显示适用资源利用率预测QoS异常指标效果最差,使用App Only的在底层和真实值有差距,使用Net Only的在应用层和真实值有差距,这恰好说明了Seer的异常预测精准度非常高.
-




【总结】
云服务促进了微服务应用的发展,本文主要关注于微服务QoS异常检测方案. 现有的QoS异常检测方案的实时性较差、基于资源利用率的检测指标不准确,据此,作者团队利用深度学习技术提出了一个数据驱动的QoS异常检测模型Seer,通过深度学习模型预测QoS异常,并通过底层硬件驱动集群管理器,对资源进行重新调度,避免即将发生的QoS异常,通过部署在集群中的微服务应用进行了实验,验证了Seer的有效性和先进性.
【后记】
本文作者团队Christina Delimitrou关注于AIOps(智能运维)领域的研究,将AI模型应用在了非CV、NLP领域,并且发挥了它的落地价值,节约了巨大的运维成本,在许多云服务商中的应用价值非常高. 改进方案可以按照如下思路:
- 对Cassandra中心化数据库可以在不影响系统性能太多的情况下,进行加密处理
- 集群扩展时,模型推理时间会显著增大,在应用扩展时,Seer的异常检测能力会大幅下降,若要在Twitter等大型社交网站上部署,还需要对深度学习模型做进一步优化,或对权重的增量学习更新机制进行更深入的设计.