
【论文阅读·推荐系统】Modelling High-Order Social Relations for Item Recommendation
以下解读均为本人个人见解,如有曲解或造成不必要的麻烦,欢迎联系我 nexisato0810@gmail.com 进行修改。正文内容中的“作者”均为paper作者本人,我的观点会由“我”或在括号“()”内显式注明。
【Paper作者】:Yang Liu, Liang Chen, Xiangnan He, Jiaying Peng, Zibin Zheng, Jie Tang,来自中山大学团队
【一句话总结】:利用GCN和注意力机制做了一个推荐系统框架,能够让我的n阶朋友影响到我的喜好.
【Introduction】
在目前的社交网络上,推荐系统是应用十分广泛的一种技术。由于类似的用户群体可能表现出相同的购买行为,因而关键在于如何使用集体智慧,这就衍生出了两种主要的推荐技术:基于内容的推荐、基于用户/物品的协同过滤推荐,这两种技术考虑到了用户购买行为之间、物品之间的相似性,但在实际的场景中,“朋友”的推荐会影响到我们的购买行为,由此引出了利用社会关系构建的推荐系统。
现有的基于社会关系构建的推荐系统(如TrustSVD)只考虑到了一阶人际关系,没有将所谓“口口相传”的传播链很好地利用起来,举例如下:
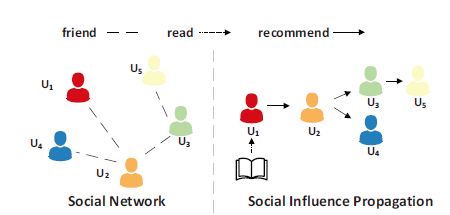
假如看到了一本书觉得不错,把它推荐给了朋友,而可能没时间看,但是他觉得的品味没问题,于是推荐给了朋友,类似地又推荐给了,这样间接地形成了一条传播链,这样的传播链在社交网络中是实际存在的,甚至可以影响到商品的定价(比如炒鞋)。
既然存在现有的一阶推荐系统模型,直接在这些模型的基础上扩展就好了,比如在TrustSVD模型中将一阶邻居替换为高阶邻居扩展用户嵌入函数。但是,这样直观的解决办法是不行的,原因有两点:
-
计算量大:对于一个用户来说,可以延伸的社交关系,会随着社交链阶级的增加而指数级增大,直接将所有高阶关系考虑进来的代价太大。
-
不同的用户应当区别对待:高阶社会关系衍生出一部分噪声,同样的推荐对于部分用户可能并不能起作用。对于一阶关系丰富的用户,现有的基于正则化的推荐方法和TrustSVD等可能已经足够,但是对于一阶关系较少的用户(朋友少)而言,建模高阶的社会关系可能更有用。要做到这样的“区别对待”对于现有的方法而言相对困难。
基于GCN,该paper提出了HOSR预测模型,通过逐步消息传播的架构实现高阶社会关系的建模,具体而言,一个GCN层通过聚合邻居的消息更新这个结点的用户嵌入函数,实现一阶信息传播,通过堆叠k个GCN层进行k步传播,这样就实现了k阶的推荐传播链。考虑到需要区别对待不同用户,作者提出了一种注意力机制自适应地聚合来自不同层的用户输入。
该paper做的工作有以下几点:
- 强调了HOSR模型在捕获潜在的长推荐传播链的重要性
- 提出基于GCN的、通过多步消息传播、将高阶社交关系显式编码到用户嵌入学习 的预测模型
- 在Yelp和Douban数据集上实验验证了HOSR模型的先进性,验证了利用高阶社会关系的有效性,尤其对于稀疏用户(朋友少)格外有效。
HOSR模型
HOSR模型主要包含:用户表征学习的GCN层+聚合每个GCN层输出嵌入的注意力机制层。
输入:用户集合,物品集合,用户-物品交互矩阵(点击或购买行为),用户-用户关系邻接矩阵
**输出:**对每个用户的映射函数 ,可以理解为用户对物品喜好的隶属度函数
用户表征学习
利用MF(矩阵分解)表征学习框架,随机初始化用户、物品嵌入矩阵,相应矩阵的第行代表第个用户(物品),列数为嵌入维度 .
首先对一阶邻居建模,两个认识的人的喜好具有相似性,对此一阶模型分为两个步骤:嵌入传播、嵌入集成。 给定用户对 ,嵌入传播可以定义为
-
表示训练权重矩阵
-
表示用户i的一阶邻居矩阵,为消息传播衰减系数
除了邻居的GCN输出嵌入,用户自身的嵌入也被作为当前结点的输入,嵌入传输过程如下图所示

由此可定义用户的一阶用户嵌入如下:
*注:此模型中tanh表现由于ReLU和sigmoid函数,由此可以精确地定义某个用户的一阶影响力传播公式。
我们已经得到了一阶影响力传播公式,通过堆叠 k 个影响力传播层(即图卷积层),用户 i 可以集成来自它的 k 阶邻居,因而i的k阶用户嵌入递归定义为
k阶嵌入传播为

如图所示,每经历一步传播,用户可以集成下一阶邻居的用户嵌入,最终过3次影响力传播后,的用户嵌入包含了整个社交网络的信息。 经历了k个图卷积层的传播后,用户嵌入定义如下:

- :经历 k 步影响力传播后的嵌入权重矩阵
- :用户嵌入矩阵,最初即
- :衰减系数矩阵,每个元素表示一个衰减系数
注意力机制层聚合
利用多层GCN,对于每个结点,我们得到了k阶的用户嵌入信息,但是问题在于:
- 少数用户的邻居是很多的,这部分用户结点不能聚合太多邻居信息,否则自身的局部性会丢失;
- 大多数用户拥有很少的邻居,它们需要堆叠多层GCN,聚合更多信息以适合提高预测准确性
这就产生了矛盾,所以大多数基于GCN的预测模型仅仅堆叠1~2层性能就达到了最佳。对此,这篇paper加入了注意力机制网络,对每个结点,评估不同阶邻居的权重再进行嵌入。权重计算公式定义如下:
将初始用户嵌入和经过l层输出的用户嵌入,利用可学习权重矩阵,分别映射到隐层,用ReLU激活后经过向量变换为注意力核心,并使用softmax计算l层GCN各自的权重系数,最终输出的用户嵌入就是各层用户嵌入与相应层权重系数的加权和。

用户所交互的物品也可以看作用户特征,所以最终用户对物品的表征输出公式定义:

模型优化分析
模型采用在排名任务中应用广泛的BPR损失函数,前提条件为:对于能被观测到的交互,其预测得分要高于未被观测到的交互行为,loss定义如下

其中 是一个由三元组组成的集合,代表被观测到的交互行为,代表未被观测到的交互行为,由此 表示二者之间边界的预测值, 代表 sigmoid函数, 代表模型参数集,模型采用RMSprop算法优化。
由于GCN容易导致过拟合,模型采用两种丢弃方法:embedding dropout随机丢弃第层某个节点的用户嵌入,减少用户对特定特征的依赖性;graph dropout在每个epoch随机切断用户的一部分社交关系,增强鲁棒性.
实验
作者利用Douban数据集和Yelp数据集进行实验,旨在研究以下问题:
-
HOSR相比于目前最先进的社交推荐系统表现如何;在稀疏数据中能否获得更好的性能
-
模型如何从注意力机制和高阶社会关系模型中获益;
-
两种丢弃策略对HOSR模型有哪些性能影响
两个数据集都是呈现长尾式分布的,多数用户只有少数邻居


采用training : validation : test = 8 : 1: 1的比例进行批量训练,采用两个指标衡量:
- Recall@K:前K个推荐项目中的正项物品 /所有正项物品(正项表示被交互的)
- NDCG@K:前K个推荐项目中正项物品的排名
二者值越大,代表性能越好。
性能对比分析

总体来看的话,HOSR模型考虑到了社会关系、考虑到了与物品的交互性、对高阶社会关系的建模相比于IF-BFR等模型更清晰精确,因此在Top-K推荐任务中表现出来的总体指标最为优越。
在稀疏数据中,作者按照用户与物品的交互次数分了4组,在不同K大小下进行对比实验,结果在Yelp数据集中表现出了较好的性能指标,在Douban数据集交互次数较少的分组中反而表现更好。

之前提到过Yelp数据集的稠密性高于Douban数据集,因此对于高点击次数的分组,数据分布相对更稀疏,说明了HOSR的高阶建模有利于相对稀疏的用户。在Douban数据集中,作者认为交互频繁的用户组没有表现出性能更好的原因在于,这部分用户组只进行用户-物品交互关系建模就足够得到用户喜好,交互次数少的用户才需要高阶社会关系建模说明。
注意力机制层分析
这部分实验将HOSR模型拆散出两个模型,进行了对比实验:一个是移除了注意力机制层的基本模型;另一个是不加权,直接使用每层输出的平均值,作为用户嵌入的模型。
结果表明,大多数情况下,引入注意力层的模型性能达到了最佳效果,这说明了不同层分别赋予不同权重的必要性和注意力机制的灵活性,且最后一层的权重明显高于其他层,这说明了高阶邻居对于捕捉到用户喜好的重要性。

超参数分析
这部分实验研究了嵌入维度和dropout的影响,结果显示模型性能会随着嵌入维度的提升而提升

dropout主要为了防止模型过拟合,且在实验中graph dropout在训练中随机切断了了用户的一部分连接关系,一定程度上提升了模型的鲁棒性。
总结
本文提出了一个能够利用高阶社交关系的推荐系统框架,将每层GCN看作不同阶的关系图,通过嵌入传播更新用户嵌入,并使用注意力机制将不同层的嵌入传播输出灵活调整,采用两种dropout策略提升模型鲁棒性,并在Douban和Yelp数据集上验证了模型的有效性。
后记
这篇paper应该是让我想到了“六度空间”理论,延长了推荐系统中的传播链,将朋友的朋友对我喜好的重要性进行了放大,并且考虑到了不同阶社会关系不同程度的重要性,在这个社交关系网络越来越庞大的今天,对于现阶段电商平台进行商品推荐有一定的指导作用。paper中用到的图卷积神经网络是近年来数据挖掘和推荐系统领域应用越来越火热的技术,但由于我对NLP和图卷积的了解并不多,因而理解可能有一些不到位或者偏差,这是需要进一步加强学习的角度。
文章的改进点可以从以下角度考虑
- 基于前人的工作可以联合考虑用户—用户关系、用户—物品交互关系对用户喜好的影响,以我的角度而言,用户对于不同物品的喜好程度,在训练过程中是如何以不同权重,受到不同阶邻居的影响,表现并不直观;
- 在社交网络中,往往一阶朋友对我自身决策的影响是最大的,用户如果存在着关系亲密的朋友,这部分用户单向受到这些朋友的影响可能会很大,因此这些关系边之间的权重是可以被指定的;
- 模型在稀疏数据上表现出了相对的优越性,但注意力机制的聚合对于稀疏关系的用户并没有表现出明显的影响,除了注意力机制外,是否有更好的聚合方法。